
By: Ruth Robinson
Objective and Background:
With the rise of the novel COVID-19 virus changing the social norms of the population in 2020 and persisting into 2021, many have individually conformed to those new social behaviors and norms that help prevent the spread of the virus while others have refused to take such precautions. Many states in America (and similarly around the world) have enforced mandates for organizations and restaurants that help stop the spread of the virus, which reinforces the social responsibilities/norms for individuals. Key government mandates are centered around enforcing actions such as:
- Required mask wearing
- Limited Capacity to encourage social Distancing
- No large gatherings
Violations of these mandates are seen throughout America on both an individual and large scale. The extent of these behaviors are difficult to quantify; however, because social media has been a means for people to discuss these violations, it may be a platform for publicly displaying or ‘reporting’ them. It would be valuable to instantaneously gather some information around these informal reports of COVID 19 violations on twitter and attribute the tweets with an authority that would be equipped to handle persistent violations that occur in a business, restaurant, or organization.
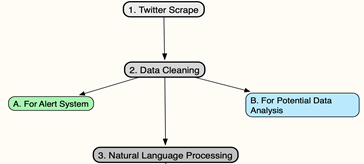 The purpose of this project is to create an alert system that notifies proper authority of potential illicit behavior informally ‘reported’ or described on social media about violations of COVID-19 restrictions. There are three major components for this project and one extended component outside the project’s scope. Using Google Collaboratory as my Python 3.6. 9 work environment, The project will involve (1) scraping twitter using targeted keywords related to COVID 19, (2) Data cleaning, for both the alert system and potential data analysis, and (3) Natural Language Processing (NLP) that will leverage the capabilities of machine learning to characterize tweets within given parameters. This project is done in collaboration with BNIA and the Maryland Mayor’s Office.
The purpose of this project is to create an alert system that notifies proper authority of potential illicit behavior informally ‘reported’ or described on social media about violations of COVID-19 restrictions. There are three major components for this project and one extended component outside the project’s scope. Using Google Collaboratory as my Python 3.6. 9 work environment, The project will involve (1) scraping twitter using targeted keywords related to COVID 19, (2) Data cleaning, for both the alert system and potential data analysis, and (3) Natural Language Processing (NLP) that will leverage the capabilities of machine learning to characterize tweets within given parameters. This project is done in collaboration with BNIA and the Maryland Mayor’s Office.
Scraping Twitter and Data Cleaning for Alert System
To scrape the tweets directly from twitter, I considered using both the traditional twitter API and the OSINT tool ‘twint’. Ultimately, I am working with twint because it has key advantages over using the Twitter API:
- Easy setup in any python work environment, compared to a long authentication process to get access to the twitter API.
- Unlike the twitter API, there is no limit to the amount of tweets that could be accessed using twint.
- There is no need to have a Twitter account to use twint
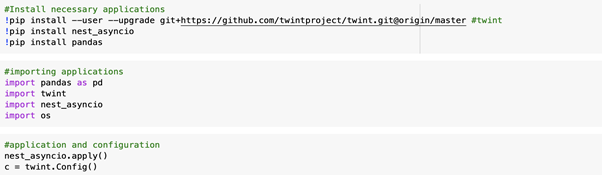
Here is the code used to install, import, and configure twint for the first search. Pandas and nest_asyncio were also installed to assist in displaying/storing the data and avoiding any unnecessary loops. ‘os’ is used to assist in saving the outgoing data.
One challenge experienced through multiple attempts of this project is the long run time for the NLP software (referenced later). Finding very targeted keywords to search is a way of combating this challenge. I compiled a list of 96 words that describe Baltimore City, specifically the bars and restaurants. Here is a map of how the data was filtered to come to a more specific and smaller dataset for NLP:
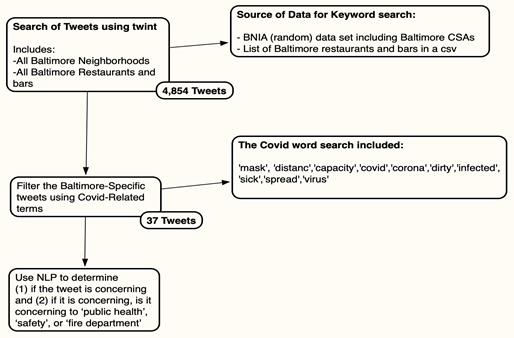 Diagram 2: Flow of Twitter-Scraped Data to NLP Data
Diagram 2: Flow of Twitter-Scraped Data to NLP Data
Creating a List of Baltimore City-Specific Search Terms for Twint
The 714 search terms include 96 Baltimore neighborhood names, 616 restaurant and bar names, and the words ‘Baltimore’ and ‘Maryland’ themselves. The source of the Baltimore neighborhood names is BNIA’s open data sets that include Baltimore’s 55 CSA’s (community statistical areas) divided by unique neighborhood names while the restaurants were provided by the Mayor’s Office of Performance and Innovation via .csv file. Compiling these search terms into a list involved some data cleaning including duplicate removal, separation of grouped neighborhood names, and combining the three smaller lists of search terms.

Scraping Twitter
Using twint, one broad search was iterated over the entire word list. For each word, I programmed twint to search for tweets, in English, bound to one day (to decrease run time), and to save the results to the local Python environment. For this project, the tweets were all posted on Saturday, December 26th, the day after Christmas.
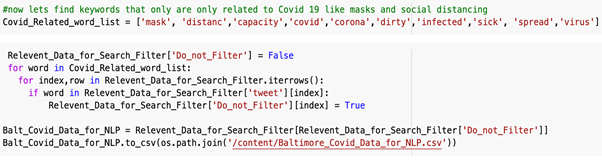
Second Keyword Filter of Twitter Data
To adequately decrease runtime for the NLP software, the Twitter data scrapped using twint has to go through a second round of filtering. Whereas the first keyword list included words specific to the Baltimore city location, this second group of keywords will be specific to COVID-19 violations. The second group of keywords are searched for within the Baltimore-specific tweets only are compiled into a new data frame if they are present in the tweets. Here is a list of those keywords and the code used to search for them among the Baltimore-Specific tweets:
Transforming the Data for Alert System vs. Analysis Opportunities
From the first tweet search, there were 4,854 Baltimore-specific tweets. These tweets were filtered further and resulted in a Baltimore-Covid-specifc data set of 37 tweets,about 0.8% of the first tweet search. To use only data that is relevant to the alert system, some columns like ‘retweets’, ‘conversation_id’ and ‘urls’ were not put into the final dataset for the NLP software either. This could be considered another filtering process that covered the ‘width’ of the data set as opposed to the ‘length’. However, the information in these additional columns are valuable for data analysis. Some data analysis questions that may be a valuable extension to this project are:
- On what days do people mostly ’report’ violations?
- What are the most common neighborhoods, restaurants, or bars mentioned in these reports?
Additional data cleaning may be involved for this kind of data analysis like changing the data types of some columns, making it easier to analyze (ie. changing the ‘created_at’ colum to a datetime datatype). The analysis could be done using the Pandas software or Numpy.
Natural Language Processing
Natural Language Processing is a relatively new concept that attempts to facilitate the communication between humans and computers using natural language. The ‘transformers’ software ‘Huggingface.co’ works by assigning a ‘score’ and a ‘label’ to a sequence. This information is derived from a trained machine learning model that evaluates the context of words within a large sets of training data. Here is an example of a sequence and the score/label assignment from the NLP software:
Sequence: “The missing masks in this place is a serious problem, we will get infected!”
Words to identify: ‘Safety’, ‘Fire Department’, ‘Public Health ’
Score: [0.4, 0.02, 0.58,]
Label: ‘Public Health’
The 37 filtered tweets (specific to both Baltimore and Covid-19) for December 26, 2020 are ran through the NLP software and was first assigned a label of ‘concerning or ‘non-concerning’. If the tweet was concerning, it was then given a label describing what or who it is concerning to. The options for these labels were ‘Politics, Public Health, Safety, Fire Department’ or ‘None’. Diagram 3 visually displays this concept:
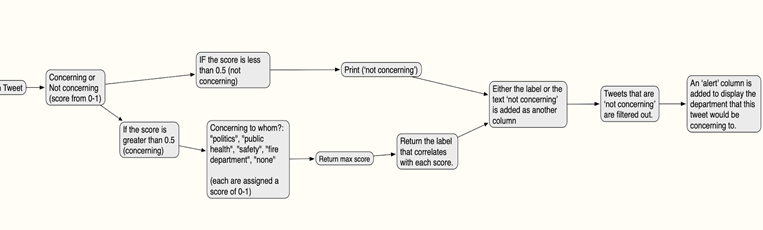
Diagram 3: How Tweet are assigned a Label
The last component of this diagram is not done by the NLP software, it is instead coded after the NLP software has assigned a label to each tweet. The ‘alert’ text was created in a new column and states ‘This is concerning to [the label]’. The Alert column would be the primary
Findings, Improvements, and Potential Points of Project Expansion
The 37 tweets that were specific to Baltimore and COVID were all labeled with either [‘Politics, Public Health, Safety, Fire Department’ or ‘None’]. The most relevant of these labels are ‘Public Health’ and ‘Safety’, which characterized 27 of the tweets (73%). These tweets are, in general, slightly off target from the objective of creating a Covid 19 alert system for Baltimore City. There are a number of issues with the resulting dataset:
- Most of the of the tweets may have included the keyword ‘Baltimore’, like a majority of the tweets but have nothing to do with Covid 19 violations in a business, restaurant, or bar.
- Some tweets did mention a maskless employee but refers to the wrong location.(ex: Baltimore Street in Hanover PA)
- There is much complaining about COVID 19 restrictions, not much reporting.
Two key improvements that would remedy these issues are (1) training a new machine learning model and (2) incentivising people on twitter to actually ‘report’ illicit behavior around Covid-19. These improvements are very much related because the primary way to get enough Baltimore Covid-19 reports (data) to train the ML model is by this incentivization of reporting on twitter through a campaign calling for such reports. Without these components, the data will very likely still have these integral issues and may not be substantial or accurate enough for an alert system.
Finally, if there are more ‘report-like’ tweets and the structural issues are able to be overcome, another extension to this project would involve creating a more user-friendly interface to house the alerts and corresponding tweets.
There is much potential for this endeavor. Using public social media data as a tool for keeping communities safe and authorities aware of community challenges is beneficial on many levels. However, even with the technology, the value of the data is determined primary by the sources. Finding ways for the public to adopt social media ‘reporting’ on a larger scale is a challenge that, if overcame, can substantially help reach local governments and communities reap these benefits.